Massive Traffic Surge to an Azure Web Application
Scenario
Are you experiencing a massive spike in both requests and outbound traffic with your Azure Web Application?
Are you also using Azure Front Door to manage traffic to that same Web Application?
Well, you have come to the right place, I might just have the answer for you.
You have the option of skipping all the gory details of my wonderful day by jumping to the Just give me the damn solution section at the bottom, or, if you’re up for a bit of a journey, join me.
Oh go on, tell me the story
The Good
Over the last couple weeks, I’ve been going through the process of migrating one of our .NET Framework apps over from another cloud provider and onto Azure Web Applications.
Everything finally came to fruition this last weekend when I finally pushed out the DNS changes to bring the site online in its new home - Hazaa.
Nothing all that special but here’s a pretty diagram with heaps of other stuff intentionally left out - helpful.
The Less Good
Skip forward a few days to Wednesday, and whilst looking at the main overview page for the app, I noticed something rather odd…
See any problems…? This is all fine… 😐 (59.4GB)
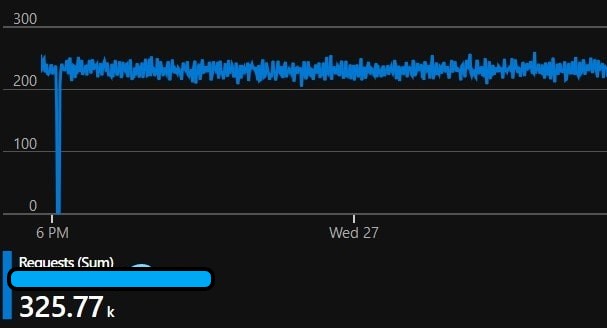
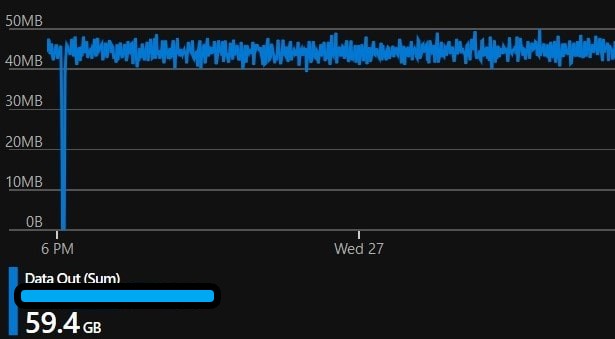
The new app was recieving an entirely unexpected number of requests, and in response, was also producing a massive amount of outbound data. In addition to that, this traffic was coming directly to the AzureWebsites origin address, skipping Azure Front Door.
Fortunately, I had also set up Application Insights as part of the migration and ran the following query.
|
|
Producing the following results.
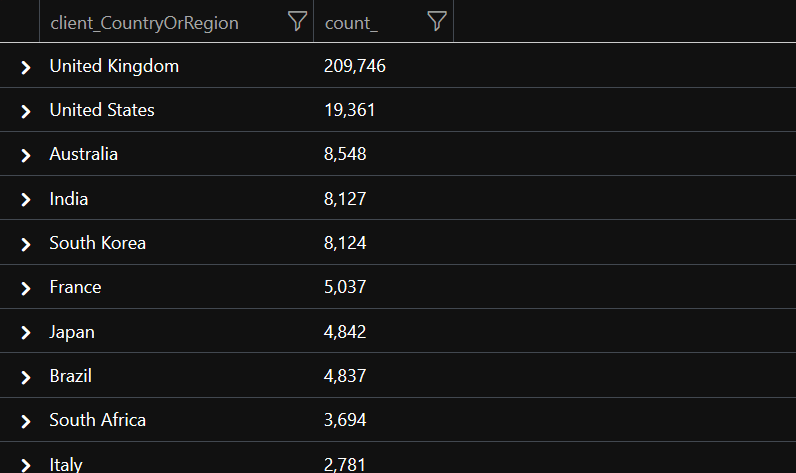
What the hell? Why are our British friends so keen on a site they can’t even use?? 🤔
The Plan
It’s fine, my plan this week was to lock down the Web Applications to only accept requests from the Front Door IP ranges anyway.
You add the IP addresses via the “Networking” tab for your Web Application, but I’ll have you know there’s 51 of those damn things!
For the time being I’ve added them to the ARM template and pushed them out via an Azure Devops Release - yay automation.
Given that the IP’s may change in future, and that the publishing method is a file download, I might need to script it some other way in future - anyway, on we go.
At the end of the process your access restrictions tab for your web app should look something like this - do not forget that bottom “Deny All” rule.
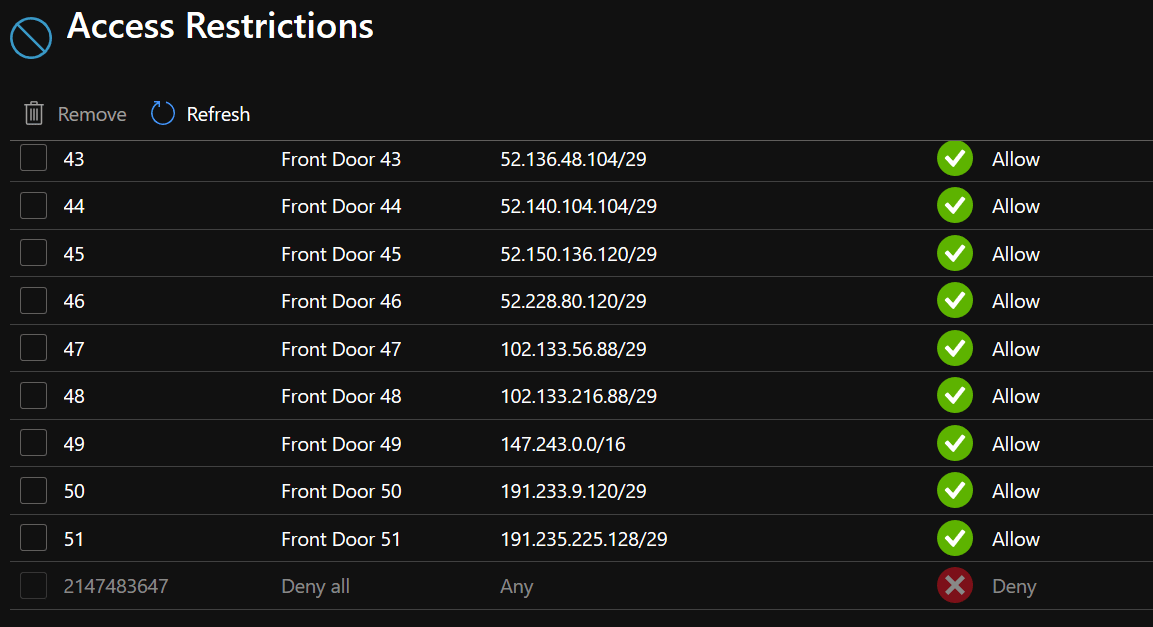
That should take care of those pesky Brits… right??
Nope! No change in the traffic! sigh 😕
I jump back into Application Insights and run a similar query, but only for the last 10 mins.
|
|
Dammit, I can still see requests coming in, let me check what Url they’re hitting now.
|
|
Unfortunately, I can still see requests to the origin AzureWebsites URL - how is this even possible??!
Application Insights does not store the incoming IP address by default, so now we need some other strategy.
I decided to enable Web Server Logging via the “App Service Logs” tab for the web application.
This allowed me to use “Log Stream” to monitor the incoming requests via the Web Server Logs.
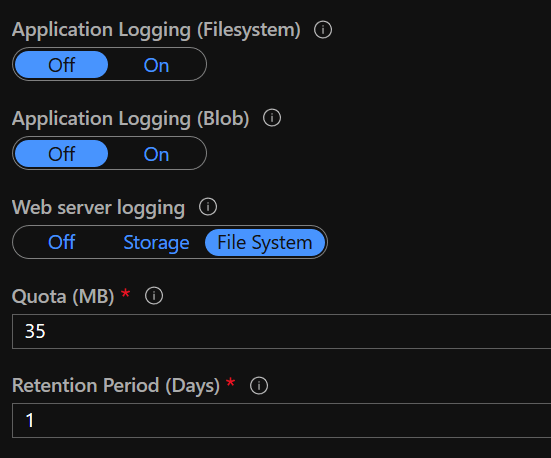
I grabbed the first IP I saw 147.243.84.106 and jumped on over to the first IP address lookup tool Google provided - and that produced the following result.
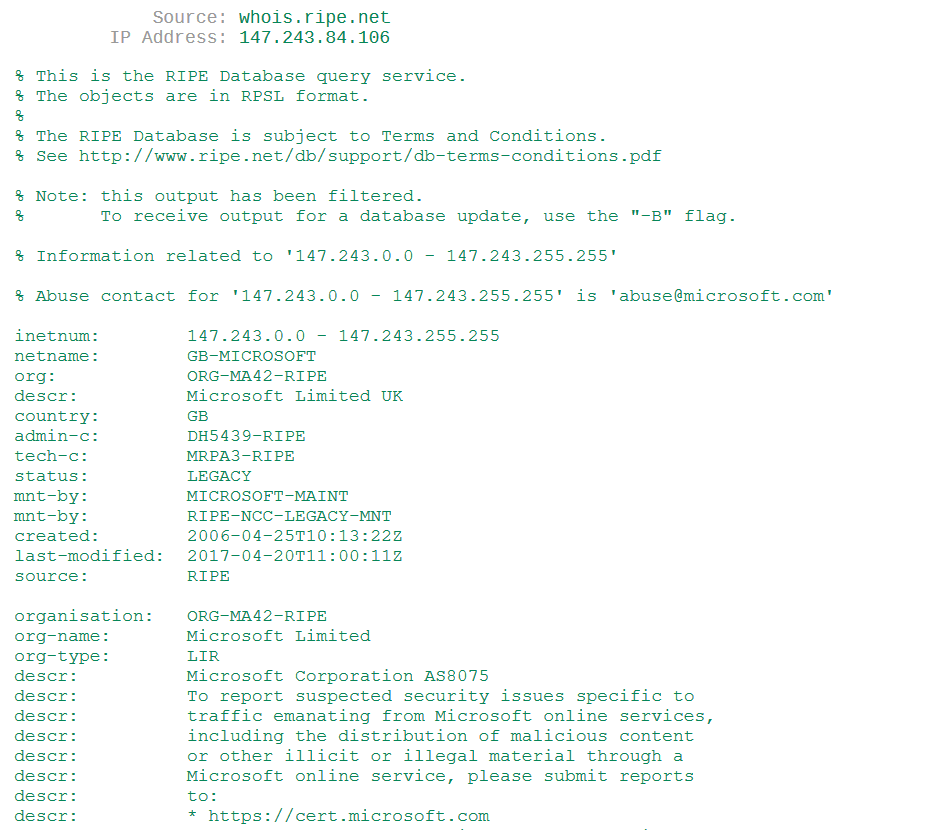
Oh no…

But, does this IP fall within the Front Door CIDR IP ranges provided by Microsoft? Ah, Yes, yes it does.
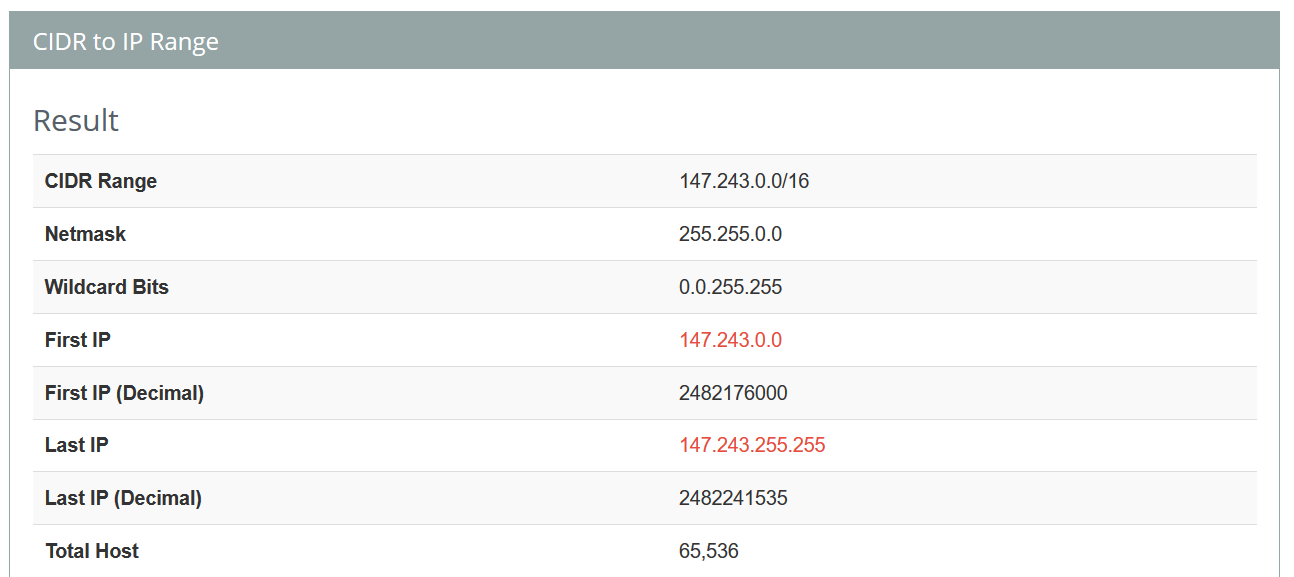
Okay, so what are my theories now - hmm
- Are there other Azure resources that are also in the Front Door ranges?
- Maybe someone has created their own Front Door Instance, and has pointed it to my App?
To deal with option 2, you need to actually check an incoming header in the request for the ID of the Front Door - argh - nooo, I don’t want the requests to get to the app in the first place!
The Plan - uhm, part 2
On a whim, I decide to kill the Front Door Instance (In Dev) - just to see what happens…
To my surprise - ALL THE TRAFFIC DROPS OFF - what the actual…!?
I redeploy the Front Door Instance and start clicking about.
I was looking through the “Backend pools” configuration in the Front Door Designer when something caught my eye… “Health Probes” - surely not… It does have a handy “Learn More” link, let me check that out.
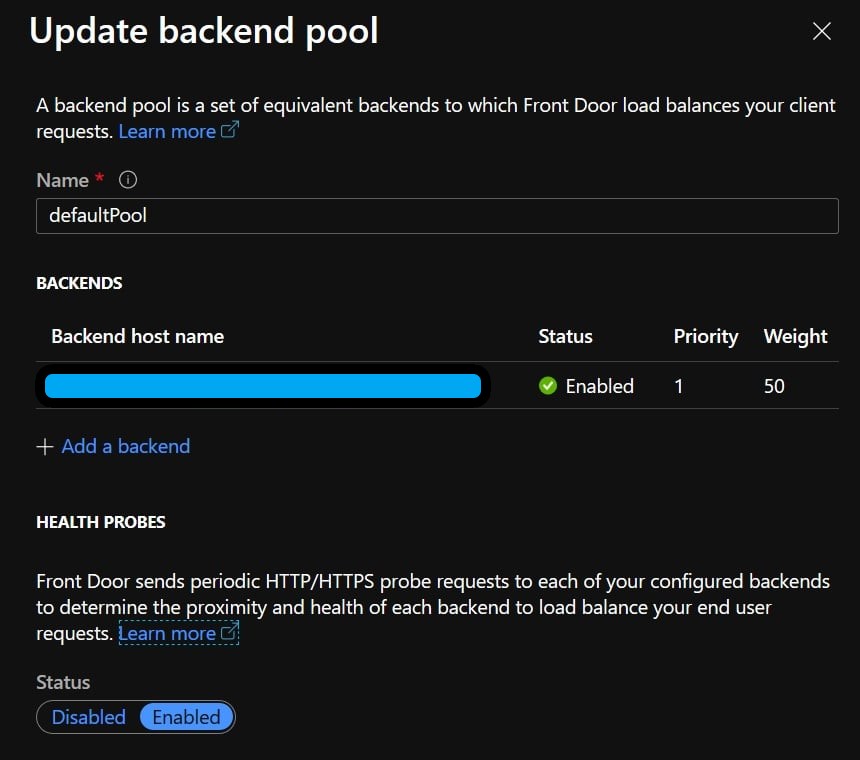
Aaaaaand, that’s a nice little warning box we have over there. Double Sigh

I disabled the health probe via the Backend Pool configuration, and what do you know, traffic drops off again - confirmed.
My strategy at this stage is to try a higher interval setting for the health probes (Max is 255 seconds) - or alternatively, disable it.
And so there you have it, if you stuck with it, then well done - hopefully, this saves you taking your own journey.
Just give me the damn solution
It’s Azure Front Door - Disable the Health Probe in the Backend Pool configuration - or increase the Health Probe Interval.
Update
After playing around with various different configurations I eventually settled on the following
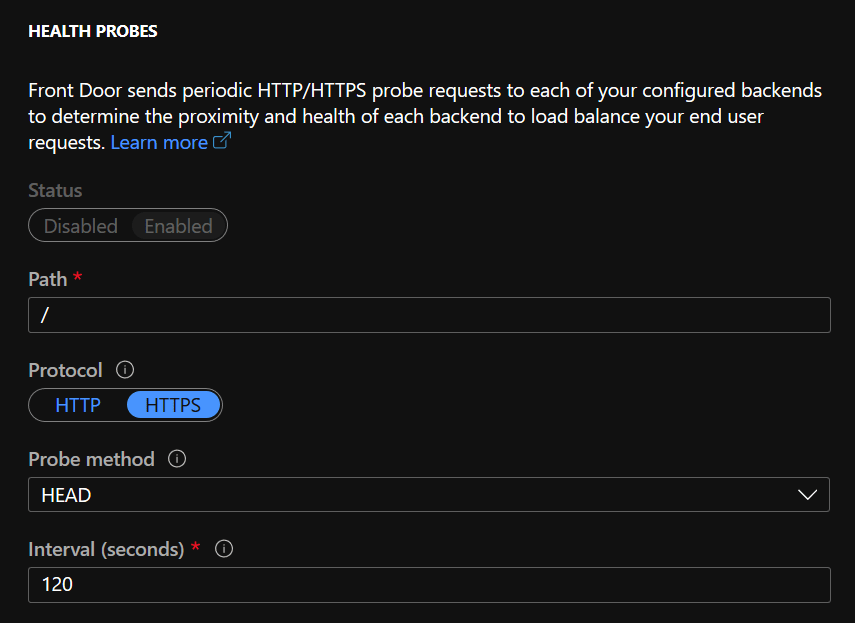
And If you’re wondering what the “HEAD” probe method means exactly
